I recently worked through Udacity’s Data Engineering Nanodegree program which consisted of four lesson plans (~5 hrs of material each): Data Modeling (PostgreSQL and Cassandra), Data Warehousing (Redshift), Data Lakes (Spark), and Pipeline Orchestration (Airflow).
This program was focused on deploying Big Data pipelines on AWS (using Redshift, S3, EMR, Glue, Athena, Lambda, etc.), but the core concepts can just as easily be applied to any cloud provider, such as Google Cloud Platform (using BigQuery, GCS, DataProc, etc.).
While online credentials are typically worthless, I found this set of courses to be fairly well curated and contain sufficient depth of explanation to make a good introduction to deploying basic ETL pipelines in the cloud. I had prior experience working in the cloud (both on AWS and GCP), so I was familiar with much of the terminology. I’ll attempt to summarize some of the key concepts from the course, but for the sake of brevity, I won’t stop at every acronym.
What’s most sorely missed in online educational materials is the synthesis between units. Each lesson plan is atomized and stand-alone. My hope is that this series of blog posts helps me synthesize these lesson plans into a single coherent introduction to Data Engineering.
What is a Data Pipeline?
The most abstract answer to this question is that a data pipeline is automated code that processes data. Typically, this is done to prepare data for a Business Intelligence dashboard or a Data Analytics team. The image below, which was presented as part of the Udacity course, provides a nice overview of a data pipeline.
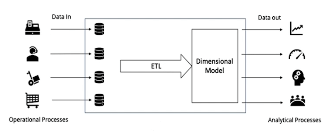
This diagram shows the basic components of a data pipeline. On the left are the Operations databases, which process the frequent transactions as part of normal business operations. These databases are sometimes called OLTP (online transactional processing) databases. Next is the ETL process (extract, transform, and load) which aggregates and summarizes the operations data into a Dimensional Model that is easier for the Analysts to process. This middle block, between the Operational data and the Analysts, is where the Data Engineer finds work. The Dimensional Model in the figure above is sometimes called an OLAP (online analytical processing) database. BI dashboards, Data Analysts, and Data Scientists run ad-hoc queries and train their Machine Learning models with this data that is prepared by the ETL process.
I once read this wonderful article by Satish Chandra Gupta that gives an excellent introduction to data pipelines for Data Engineers and Data Scientists.
One refreshingly cogent diagram in this article, shown below, shows a comparison of cloud services used in an end-to-end data pipeline. From data acquisition and ingestion to data storage and processing and finally to EDA (exploratory data analysis) and visualization. Not only does this diagram illuminate some of the meaning behind the inscrutable names of cloud services by showing them in their relative position in a data pipeline, but it also illustrates a uniformity between the offerings of the various cloud service providers.
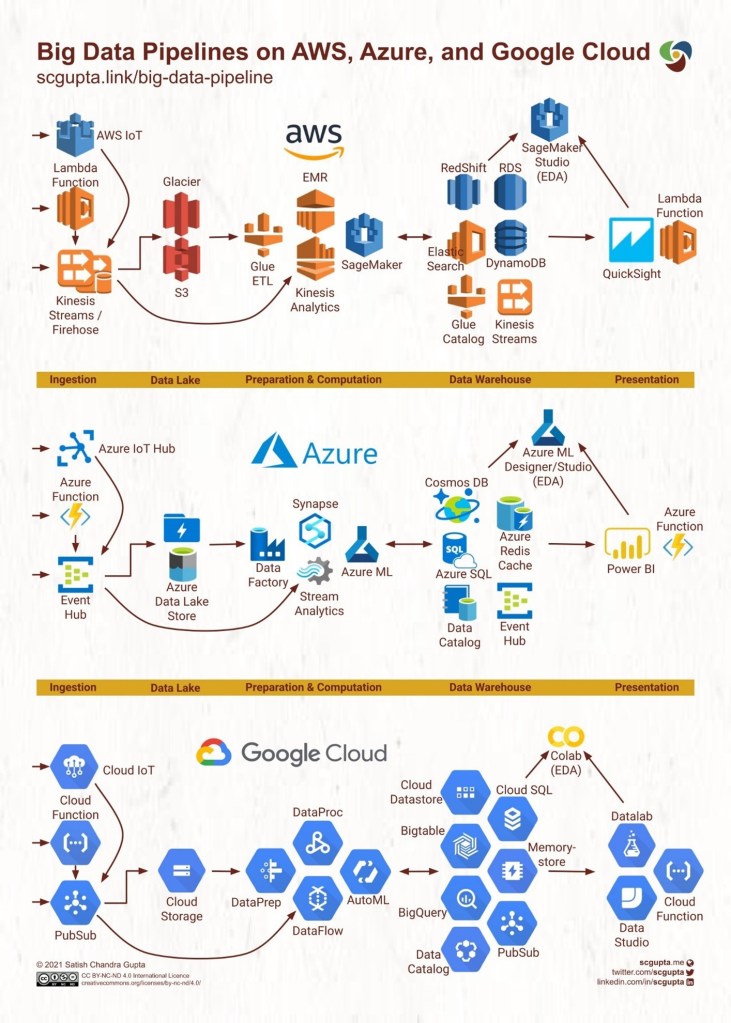
In the diagram above, he uses Ingestion, Data Lakes, Preparation and Computation, Data Warehouse, and Presentation. If we were to use the ETL acronym, the pipeline above would be an ELTLV (extract, load, transform, load, and visualize) pipeline. Not to mention the “A” for the Analysis tools that are added at the end, marked by the “(EDA)”. This diagram was the first time I saw where Data Science and Machine Learning fit into the broader scope of an organizations data infrastructure. And as we will discuss in a later post, Data Scientists also interact with the Data Lake to perform distributed machine learning tasks.
If I had to pick only one difference between Data Science and Data Engineer, it would be the difference between Ad-Hoc analysis and Scheduled (read automated) ETL processing. Both disciplines interact with machine learning algorithms and both require quite a bit of coding and statistical knowledge, but Data Science is more interested in discovery while Data Engineering is more interested in delivery.
In the next post, I’ll start talking about the beginning of this pipeline, the OLTP databases.
