
New deep learning tools such as BERT, the open-source transformer model, were all the rage in the NLP world when we began this class project. The point of NLP (natural language processing) is to automatically “read”, or summarize, lots of unstructured text, and transformer models are a new architecture of deep learning models that can perform these summarization tasks quite well. The excitement around this new deep learning architecture motivated my classmate and I to turn our Data Mining project into an NLP project that utilized these new deep learning architectures.
The full paper can be found on my GitHub, here. In brief, this project showcases my experience with NLP, social media data mining, machine learning, and technical writing.
Why Nuclear Energy?
Nuclear energy plants live or die by local politics. For this reason, nuclear energy interest groups have been conducting regular polls to gauge people’s opinions on the various aspects of nuclear energy for decades. We saw this as long history of survey literature as an opportunity. Specifically, we were able to compare the results from our machine learning models against the established survey literature to validate our methodology. We saw this as a great opportunity to validate the new transformer architectures using real-world data!
We had another motivation for the project as well. California was very publicly closing down its last remaining nuclear power plant which single handedly produced 20% of the state’s 0-emission electricity. Around the start of this project, we heard news reports of rolling blackouts in California due to wild fires interrupting renewable energy generation and began to wonder if we could measure the time series of sentiment changes in response to major event as previous research had done. Perhaps rhetoric around nuclear energy might become more positive in response to rolling blackouts, we wondered. To investigate, we had to collect a large dataset of tweets relating to nuclear energy.
Data Collection
We accessed the Twitter API using the tweepy python wrapper to collect over 50,000 nuclear energy-related Tweets in real time from about 25,000 unique user accounts within the United States. We identified relevant tweets that contained one of the following keyword phrases: “nuclear energy”, “nuclear power”, “nuclear waste”, “nuclear radiation”, “nuclear reactor”, “nuclear accident”, and “radiation pollution”. Naturally, the topics of nuclear energy and nuclear weapons exhibit significant overlap, so to prevent the oversampling of Tweets related solely to nuclear weapons, we used the above keywords in conjunction such that all relevant Tweets returned by the API must have both key words in their text, e.g. both “nuclear” and “energy”. We then filtered the resulting dataset for users who were identifiably within the US.
Methodology
The two main machine learning algorithms that we implemented were LDA and the deep-learning transformer models.
LDA is a classic unsupervised machine learning algorithm for topic analysis (link to the original 2003 paper, here). Topic Analysis is a way of clustering words from a large collection of documents based on whether the words commonly appear together. A “topic” in this model is just a collection of words, and a good model will reveal a ranked order of human-interpretable topics from these word clusters. Furthermore, a trained LDA model can be used to identify the topics that are present within new documents that were not in the training dataset. Here is a good introductory video series on the Dirichlet distributions used to create these topic models.
BERT is one of the many new open-source deep learning transformer models that’s design for NLP tasks such as sentiment analysis. (Link to the original transformer paper here, and BERT paper here). Sentiment analysis is a way of labeling a document with one of three labels: positive, neutral, or negative (SA can have anywhere between 2 and 10 labels, but 3 labels struck the balance we needed for our analysis). In this project, we trained BERT on a large dataset of Tweets that were unrelated to nuclear energy and then used the trained model to make predictions about our curated dataset (This is an example of what is known as “transfer learning” for deep learning models). This means that our sentiment analysis result is a label on the rhetoric of the Tweet rather than the user’s true beliefs or opinions of nuclear energy. This could be considered a current limitation of the state-of-the-art deep learning NLP models. Regardless, these models achieve a far better performance than the traditional lexical approach, e.g. VADER in python.
Another (fairly obvious) limitation of the current state-of-the-art models is that they still fail to recognize highly rhetorical speech like irony, jokes, and sarcasm, which, unfortunately for our case, are highly common on social media platforms. Despite this, we obtained similar results to published pollster data on a variety of metrics which gives us confidence in our results.
Results
Let’s dive right in. We found that 67 percent of users in our dataset primarily expressed positive sentiments towards nuclear energy, and more interestingly, that men and older people express more positive sentiments than women and younger people, respectively. Both of these findings are backed up by survey analyses in Bisconti (2021). In the figure below, we use the positive to negative ratio of sentiment labels to illustrate relative sentiment. By presenting our results as a ratio, we are normalizing for time periods when emotions are high and emotionally charged language is being used on both sides of the debate.
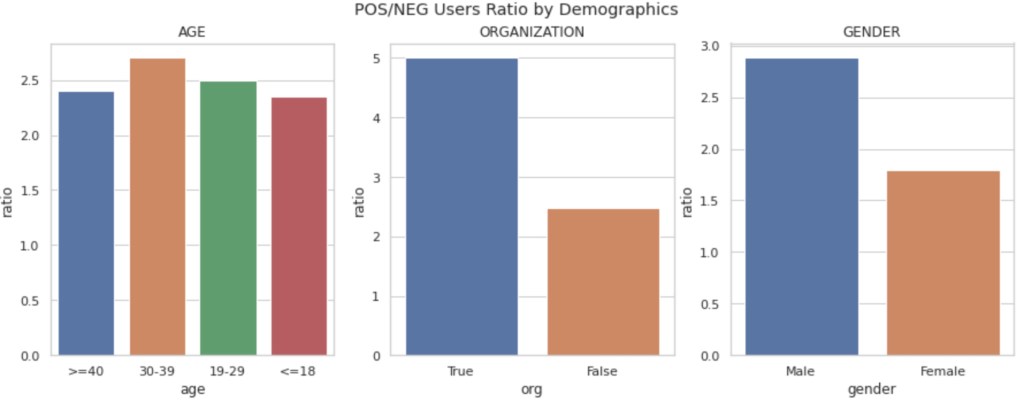
We combined our sentiment analysis and our topic analysis results to find that accounts belonging to organizations are the predominant advocates of nuclear energy as a potential aid in addressing climate change, while accounts belonging to individuals, particularly women and young people, tweeted more about the threats posed by nuclear weapons and accidents. Cross-sectional results like this are examples of novel results from this methodology that aren’t present in the survey literature.
LDA revealed that the major topics in our dataset, in order of prevalence, were Nuclear Waste, Climate Change, Radiation and Accidents, Safety, and Reactor Design. Sample tweets from each of the top five topics are presented below (url links and images omitted):

Finally, by filtering individual user locations by state, our analysis reveals that California Twitter Users are, on average, “pro-nuclear”. Individual users reporting to be living in California had a positive to negative sentiment ratio of 2.53, which is a significant majority. The motion to shut down Diablo Canyon, California’s last operational nuclear power plant, has the potential to be reversed if legislatures choose to classify nuclear energy as “green energy”. Our results seem to suggest that the debate over the closure of Diablo Canyon is far from over.
Final Thoughts
For me, the exciting thing about this project is that this methodology isn’t limited to discussions of a single topic like nuclear energy. By changing the keywords when accessing the Twitter API, this pipeline could be used to analyze just about any political issue or social trend in real time. The API can follow keywords, hashtags, user accounts, user mentions, etc. It could be used to track political movements, political candidates, public health trends, and pandemics. The primary limitations of the data collection is that the API connection must be established in advance to collect Tweets in real-time. In a sense, you have to be ahead of the trend to track it.
On the NLP side of the project, there are several limitations regarding the current state-of-the-art transformer models. Our best performing model achieved an F1 score of 0.801 on sentiment analysis, which is quite good compared to traditional methods, but still, the model is still a low-level rhetorical interpreter and does not understand underlying beliefs or higher-level rhetoric like irony, humor, or sarcasm. Until then, these models aren’t going to replace traditional survey methods. Additionally, Twitter, like most social media platforms, are multi-media, and each post has external links to articles and images. The pipeline that we built for this project simply ingests the text and user metadata of the Tweet, not the media.
When starting the project, I was most excited to get experience working with these machine learning algorithms, as well as getting familiar with the numerous steps in of NLP preprocessing pipelines. Now that I’m familiar with them, I’m excited to apply these models in future projects as well.
